We present PORTAL, a novel framework for developing artificial intelligence agents capable of playing thousands of 3D video games through language-guided policy generation. By transforming decision-making problems into language modeling tasks, our approach leverages large language models (LLMs) to generate behavior trees represented in domain-specific language (DSL). This method eliminates the computational burden associated with traditional reinforcement learning approaches while preserving strategic depth and rapid adaptability. Our framework introduces a hybrid policy structure that combines rule-based nodes with neural network components, enabling both high-level strategic reasoning and precise low-level control. A dual-feedback mechanism incorporating quantitative game metrics and vision-language model analysis facilitates iterative policy improvement at both tactical and strategic levels. The resulting policies are instantaneously deployable, human-interpretable, and capable of generalizing across diverse gaming environments. Experimental results demonstrate PORTAL's effectiveness across thousands of first-person shooter (FPS) games, showcasing significant improvements in development efficiency, policy generalization, and behavior diversity compared to traditional approaches. PORTAL represents a significant advancement in game AI development, offering a practical solution for creating sophisticated agents that can operate across thousands of commercial video games with minimal development overhead.
A policy
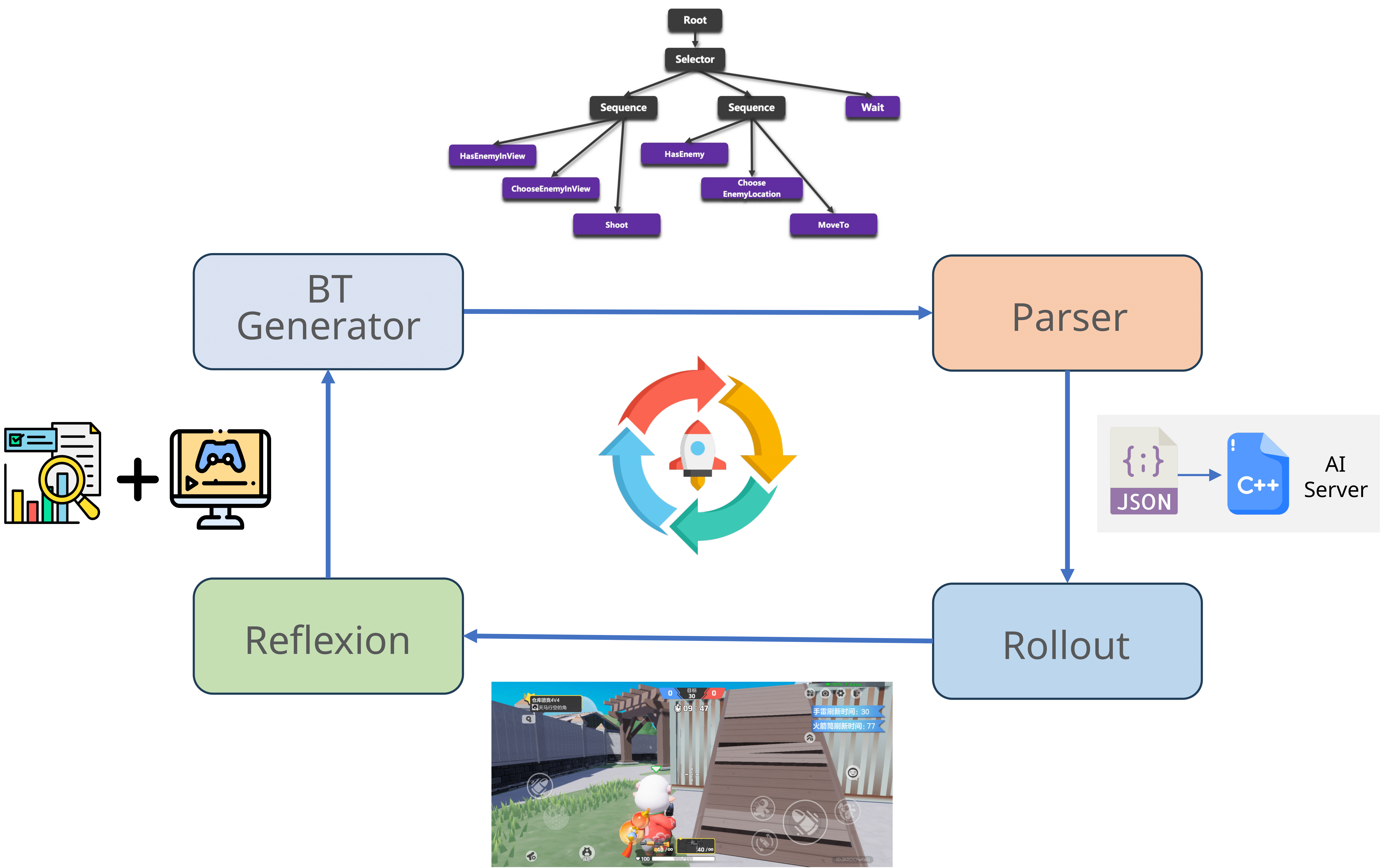
The Behavior Tree (BT) Generator produces DSLs and JSONs for each policy, which can be parsed to run the corresponding behavior tree in the game. We collect rewards and visual feedbacks to perform Reflexion for the LLMs.
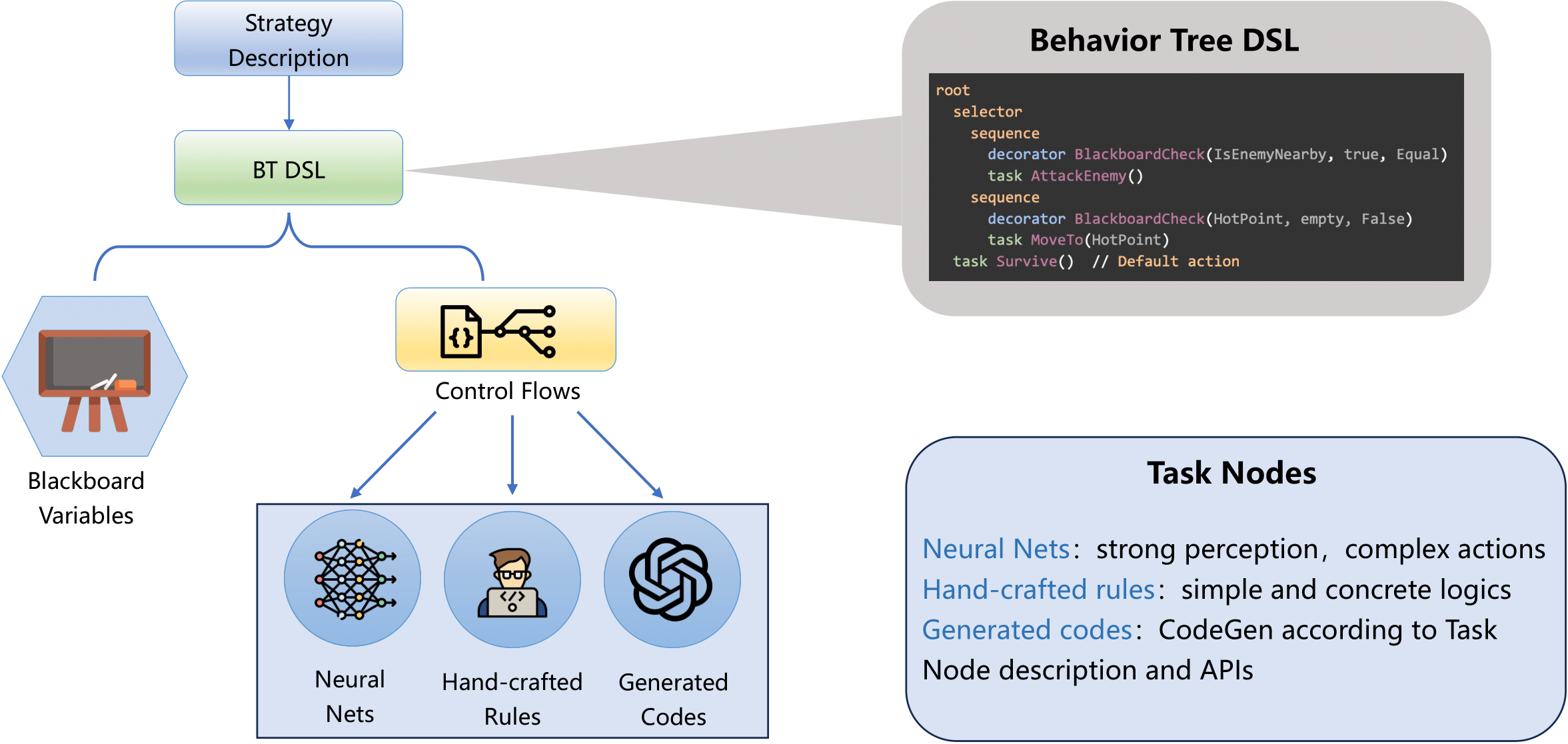
Here we illustrate how we structure the Behavior Tree (BT) with Control Flows and Task Nodes, where the task nodes could be neural networks, ruled-based nodes and LLMs-generated nodes. Note that the neural nets here are not giant LLMs but just two layers of fully-connected layers / Convolutional layers.
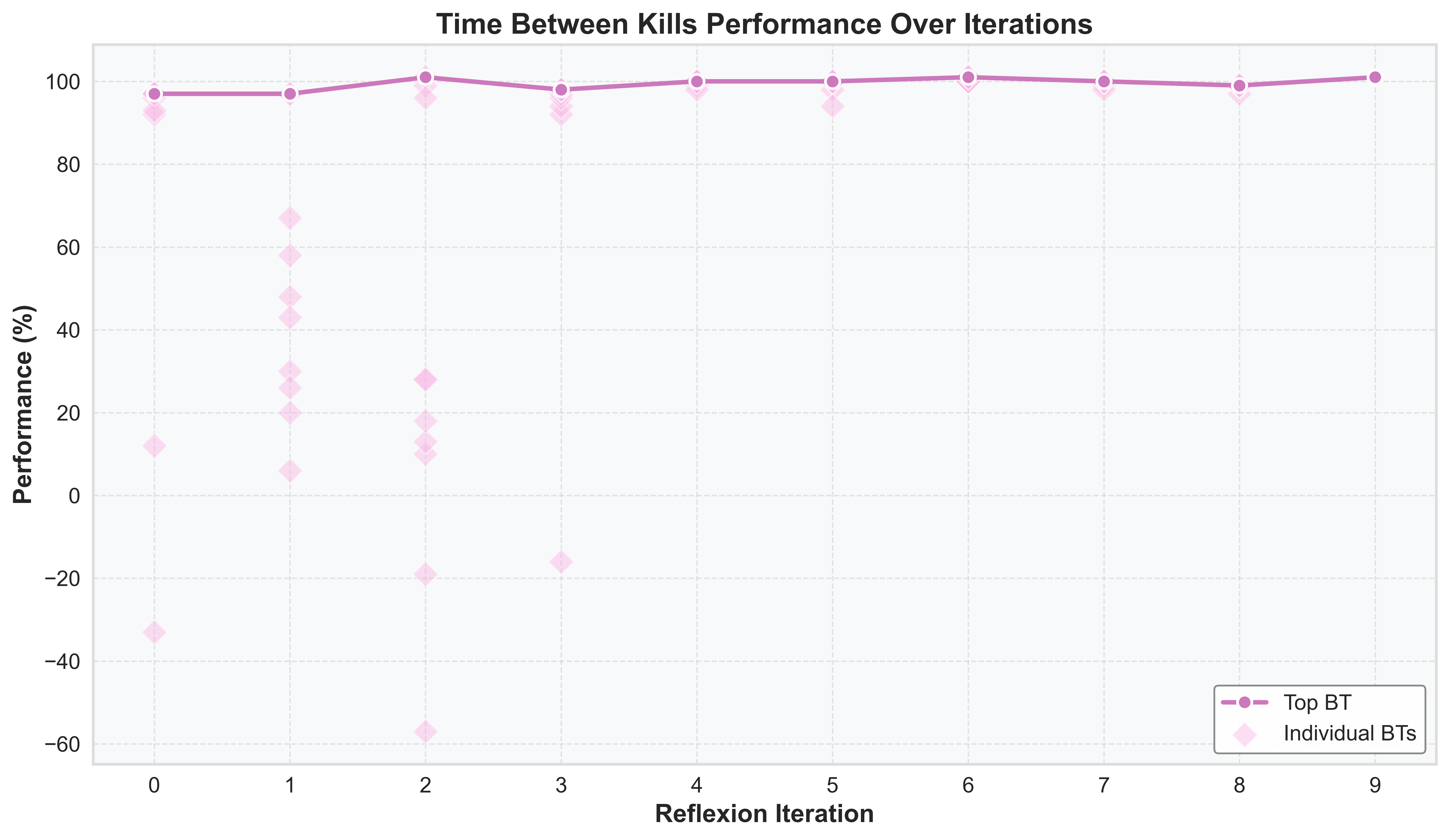
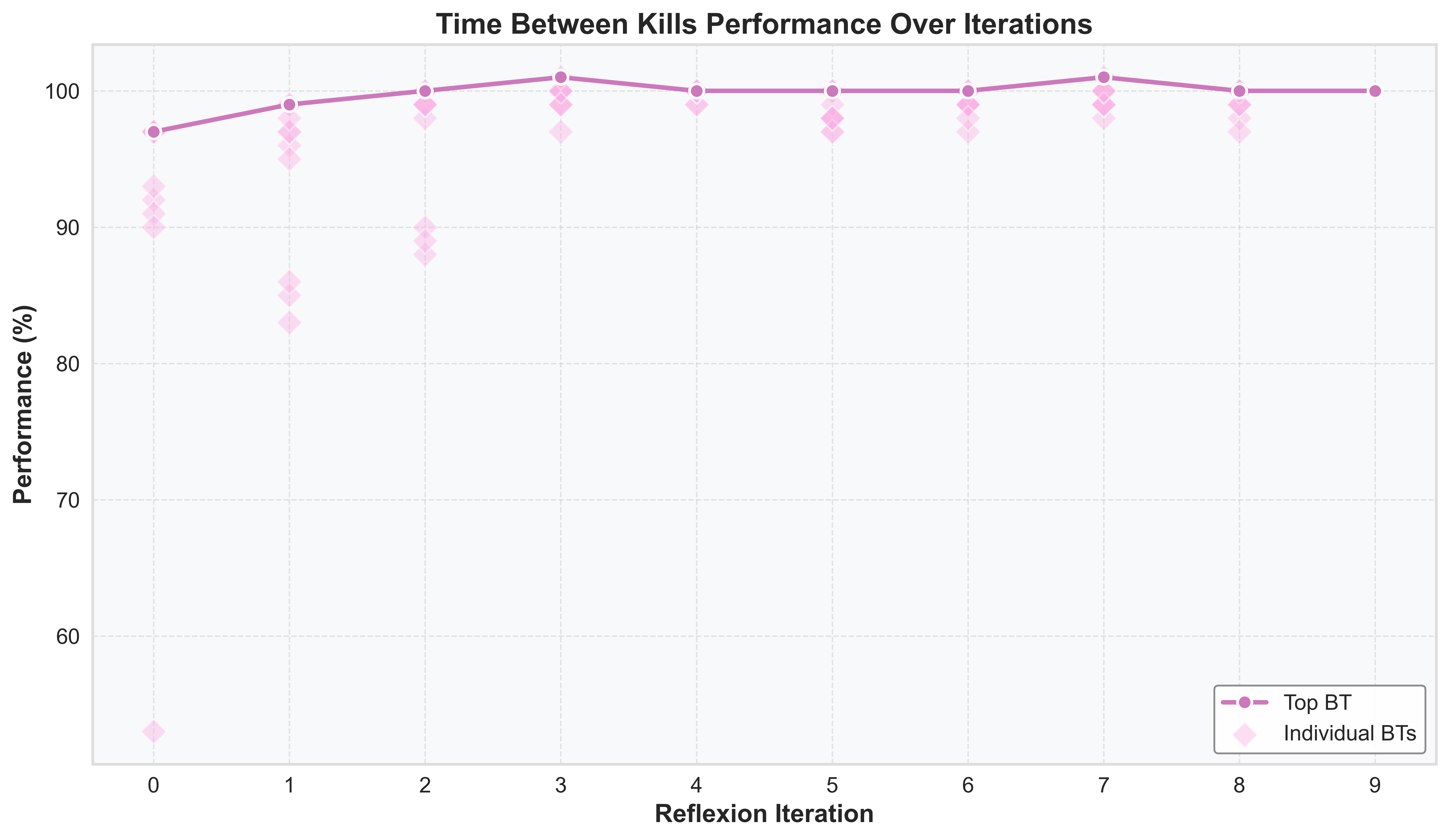
We show the optimization of game metrics over Reflexion iterations during the Breadth-First Search (BFS) process, where the top 10 policies converge gradually.
Here we show some examples of policies generated by PORTAL. You are strongly encouraged to check out the illustrations, DSL and JSON files for more details. Due to copyright restrictions, we cannot provide demonstrations across the thousands of user-generated content (UGC) games tested. However, you could imagine how cool it is by just expanding these grids!
General Policy (BT Illustration, DSL, JSON)
Team Attack (BT Illustration, DSL, JSON)
Advantage Point (BT Illustration, DSL, JSON)
@article{xu2025agents,
title={Agents Play Thousands of 3D Video Games},
author={Xu, Zhongwen and Wang, Xianliang and Li, Siyi and Yu, Tao and Wang, Liang and Fu, Qiang and Yang, Wei},
journal={arXiv preprint arXiv:2503.13356},
year={2025}
}{kind=link}
{kind=link}
{kind=link}